Remote IoT Batch Job Example - AWS
Table of Contents
- What is a Remote IoT Batch Job in AWS?
- How Do Remote IoT Devices Collect Information?
- Why Use Batch Jobs for IoT Information?
- Where Does AWS Fit into Remote IoT Batch Jobs?
- A Simple Remote IoT Batch Job Example in AWS
- The Flow of Information in a Remote IoT Batch Job
- Making the Batch Job Process Information
- Putting Together a Remote IoT Batch Job
When you think about things out in the world, far away, sending little bits of information back home, that's a bit like remote IoT. We are talking about sensors on a farm, maybe, or machines in a factory that is not right next door. These things gather facts and figures, and then, at some point, that information needs to be looked at, all at once. This looking at information all at once, in big groups, is what we call a batch job. So, putting those two ideas together, a remote IoT batch job in AWS means gathering information from far-off devices and then processing it in large chunks using Amazon's cloud services.
This way of handling information is pretty helpful, you know, especially when you have a lot of stuff coming in but you do not need to react to every single piece right away. It's like collecting all your mail for the day and then sitting down to sort through it all at once, rather than stopping what you are doing every time a new letter arrives. That, in some respects, makes things run a bit smoother, letting you get a good overall picture of what is happening with your remote devices without constant interruptions.
The cloud, specifically AWS, gives us a place to do all this. It provides the tools and the space needed to store the incoming information and then to run those big jobs that make sense of it all. This setup is quite useful for many kinds of projects, allowing for a good way to manage data from many places. It is, you know, a very common way to work with information from devices that are not physically close to you.
- Unveiling The Life Of Prince Edwards Daughter
- Exploring The Lives Of Lilibet And Archie The Next Generation Of Royalty
- Simone Biles The Journey Of Pregnancy And Motherhood
- Exploring The Life And Love Of Neil Tennant And His Couple
- What Happened To The Cast Of Everybody Loves Raymond Now
How Do Remote IoT Devices Collect Information?
Remote IoT devices are, you know, basically small pieces of equipment that can sense things in their surroundings and then send that information somewhere else. Think about a sensor that checks the temperature in a field, or a device that keeps track of how much liquid is in a tank that is far away. These devices are often powered by batteries and need to be efficient with their energy use. They gather their little bits of information, like a temperature reading or a pressure level, and then they need a way to get that information to a central spot.
The way they send this information can vary quite a bit. Sometimes, they might use a wireless connection, like Wi-Fi, if it is available. Other times, for devices that are really out there, they might use cellular networks, just like your phone does, or even satellite connections. The goal is always the same: get the data from the device to a place where it can be stored and looked at. This sending of information is, for the most part, a continuous process, even if the device only sends data every few minutes or hours. It is, you know, a steady stream of little facts and figures coming in.
When this information arrives at its destination, it is usually in a raw form. It might just be a number, or a timestamp with a reading. Before it can be truly useful, it often needs some kind of processing. This is where the idea of a remote IoT batch job example in AWS starts to make a lot of sense. You gather all these individual pieces of information over a period, perhaps a day or a week, and then you process them together to find patterns or make decisions. It is, in a way, like collecting all the pieces of a puzzle before you start to put it together.
- Unveiling The Life Of Arbaaz Khan The Journey Begins
- Discovering The World Of Yesmovies Your Ultimate Guide To Streaming
- Exploring The Charismatic Journey Of Raj In The Big Bang Theory
- Logan Pauls Charizard The Iconic Pokmon Card That Took The Internet By Storm
- Taylor Swift A Journey Through Her Hometown
Why Use Batch Jobs for IoT Information?
You might wonder why we would wait to process information in a batch, instead of looking at it right away. Well, there are a few good reasons for this, especially when we are talking about remote IoT information. For one thing, not all information needs to be acted on instantly. If you are tracking the soil moisture in a large field, you probably do not need to know the exact moisture level every second. Knowing the average over an hour, or the total change over a day, is often more useful. This means you can gather a lot of readings before you do any heavy thinking about them. That, actually, saves a lot of computing effort.
Another reason is efficiency. Running a big computing job once, on a large collection of information, can be more efficient than running many small jobs on individual pieces of information. Think about it like doing laundry. It is generally more efficient to wait until you have a full load and run one wash cycle, rather than washing one sock at a time. This approach, for a remote IoT batch job example in AWS, means you can use computing resources more effectively, which can also help keep costs down. It is, you know, a smarter way to handle large amounts of data.
Batch jobs are also good for tasks that take a lot of computing power. Maybe you need to run complex calculations on a week's worth of sensor data to predict future trends. Doing that on a single sensor reading would be pointless, and doing it constantly would be very expensive. By collecting all the data and then running a powerful batch job, you can get those insights without constantly using high-end computing resources. So, it is a way to get a lot of work done at specific times, rather than having things running all the time. This, in some respects, is a very practical approach for many data processing needs.
Where Does AWS Fit into Remote IoT Batch Jobs?
AWS, which is Amazon Web Services, provides a whole set of tools and services that are really good for handling remote IoT information and running batch jobs. Think of it as a very big toolbox with everything you might need for working with data. When information comes in from your remote IoT devices, AWS has services that can safely receive it, no matter how many devices you have or how much information they are sending. This is, you know, a big part of why people choose cloud services for this kind of work.
For receiving information, AWS IoT Core is a key service. It acts like a central hub where all your remote IoT devices can send their readings. It is built to handle a huge number of connections and a lot of incoming information. Once the information arrives there, you can then direct it to other places within AWS for storage. This makes sure that every piece of information from your remote IoT batch job example in AWS gets where it needs to go without getting lost. It is, for the most part, a very reliable way to get data from many different sources.
Then, for storing the information, services like Amazon S3, which is a simple storage service, are very useful. S3 is like an endless bucket where you can put all your raw information. It is very durable, meaning your information is safe, and it can store truly massive amounts of data. This is important because remote IoT devices can generate a lot of information over time. After the information is stored, AWS also offers services for running the batch jobs themselves. These services can spin up powerful computers just when you need them to do the heavy lifting of processing your collected information. So, you know, it is a complete environment for managing data from start to finish.
A Simple Remote IoT Batch Job Example in AWS
Let's imagine a very simple scenario to make this whole idea clearer. Picture a farm that has many sensors spread across its fields. These sensors are, you know, checking things like soil moisture levels, air temperature, and maybe even sunlight intensity. They are all remote IoT devices. Each sensor sends its readings back to a central system every hour. The farmer does not need to know the exact moisture level every single second, but they do want to know the average moisture level for each field at the end of the day, or perhaps if any field's moisture dropped below a certain point overnight. This is a perfect setup for a remote IoT batch job example in AWS.
So, throughout the day, each sensor sends its hourly readings. These readings, which are small bits of data, arrive at AWS. They get collected and stored in a designated spot. At midnight, or perhaps early in the morning, a specific job is set to run. This job does not run all the time; it only runs at that particular time. Its purpose is to go through all the sensor readings that came in over the last 24 hours. It will calculate the averages, check for any low moisture readings, and then put all that summarized information into a report. This report is what the farmer actually uses to make decisions about watering or other tasks. That, you know, is the core idea of a batch job.
This approach means the farm's system is not constantly working to process every single reading as it arrives. Instead, it waits, collects everything, and then does the heavy work all at once. This makes the system more efficient and often less costly to operate, because you are only paying for the computing power when you are actually using it for the batch job. It is, for the most part, a very practical way to manage data from many devices that are spread out over a large area. This kind of remote IoT batch job example in AWS is quite common in many industries.
The Flow of Information in a Remote IoT Batch Job
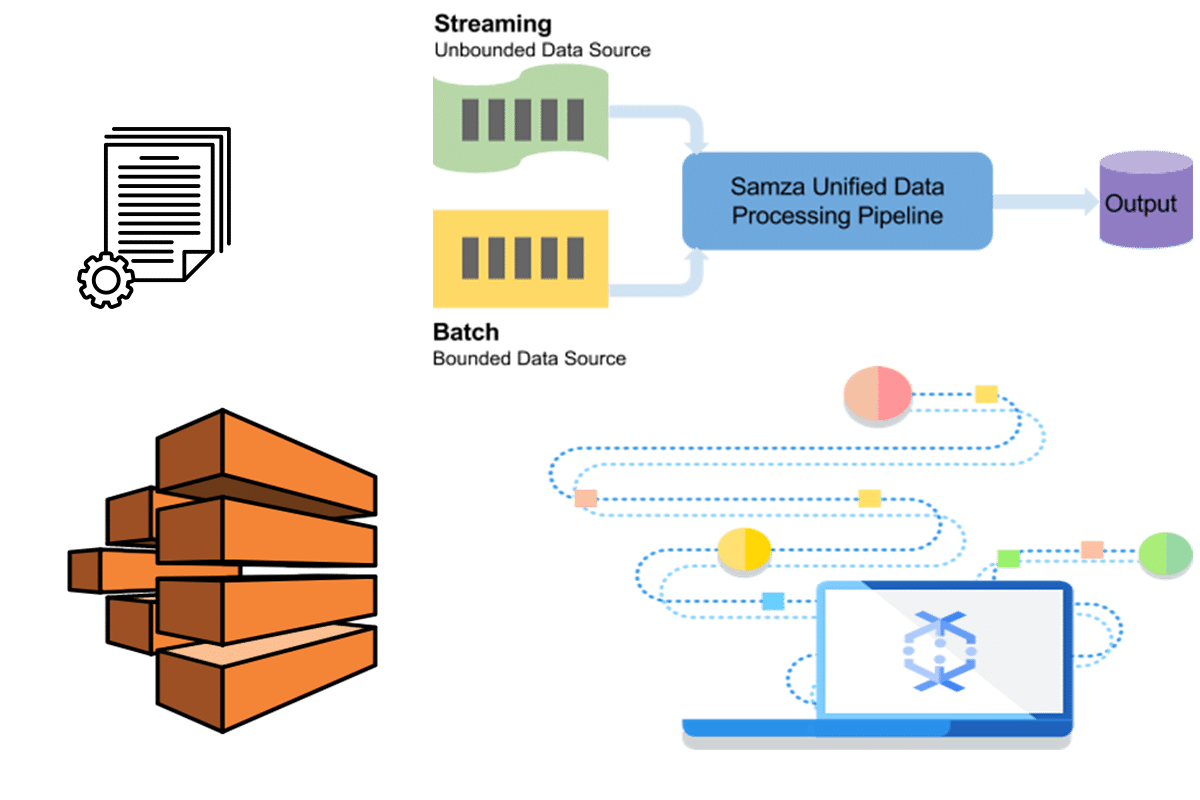
Let's trace the path of information in our farm sensor example, focusing on how it moves through AWS for a remote IoT batch job. First, the remote IoT sensors in the fields take their readings. These devices are set up to send their information, perhaps every hour, over a wireless connection. This information, like a temperature reading of 25 degrees Celsius or a soil moisture reading of 60%, is then sent to AWS. This is, you know, the very first step in the journey of the data.
When the information arrives at AWS, it first goes to a service called AWS IoT Core. Think of IoT Core as the front door for all your remote IoT devices. It is designed to handle a lot of incoming information from many devices at once. IoT Core has rules that tell it what to do with the incoming information. For our example, the rule might say: "Take all incoming sensor readings and send them to an S3 bucket." So, every hourly reading from every sensor gets placed into a special storage area in S3. This happens continuously throughout the day. It is, in a way, like dropping letters into a mailbox, one by one.
Throughout the day, the S3 bucket slowly fills up with all the raw sensor readings. Each reading is a small file, or part of a larger file, with a timestamp and the actual measurement. This collection of raw information is what the batch job will eventually work with. The information sits there, waiting to be processed. This setup is quite good because S3 is very good at storing large amounts of data at a very reasonable cost. That, actually, makes it a very popular choice for this kind of data storage in a remote IoT batch job example in AWS.
Making the Batch Job Process Information
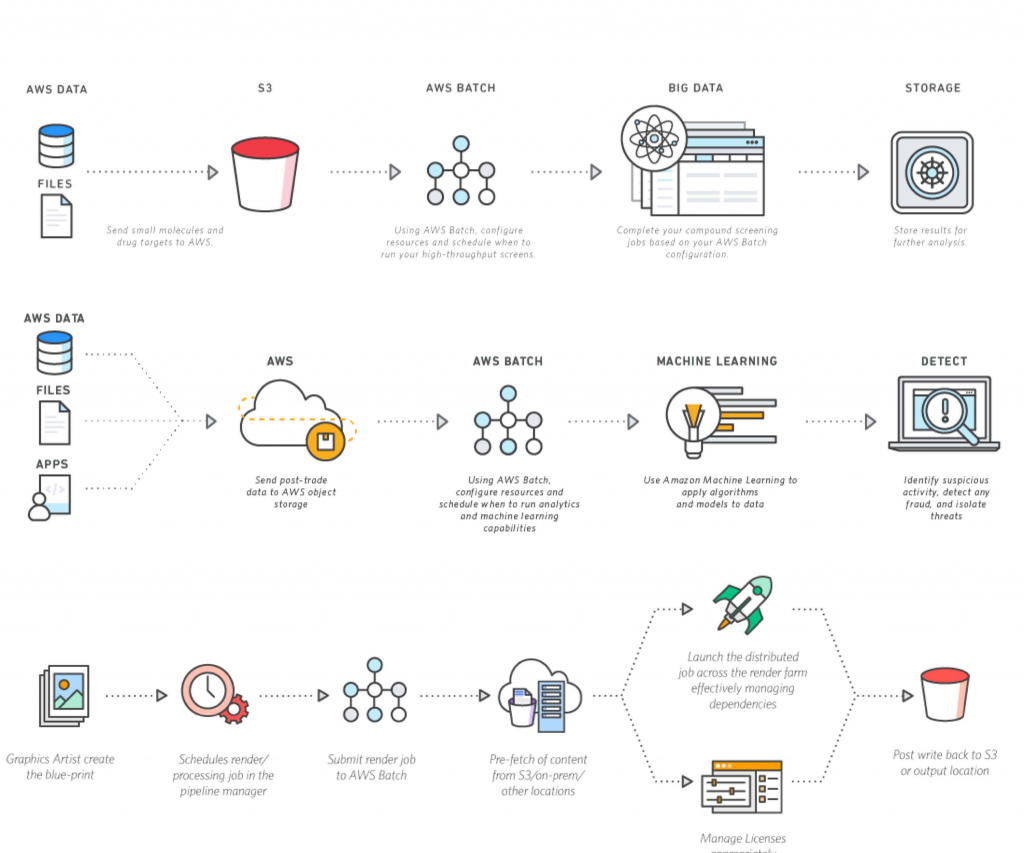
Now that all the sensor readings are gathered in S3, it is time for the batch job to do its work. To start this job, we might use something like AWS Lambda or AWS Step Functions. Imagine Lambda as a small, quick worker that can be told to do a specific task. We can set up a Lambda function to be triggered at a specific time, say, midnight. When midnight arrives, this Lambda function starts running. It is, you know, the signal for the batch process to begin.
The Lambda function's job is to kick off the main processing part of our remote IoT batch job example in AWS. It might, for instance, tell another AWS service, like AWS Glue or AWS Batch, to start working. AWS Glue is a service that is very good at preparing and processing large amounts of data. It can read all the sensor readings from S3, understand their format, and then run various calculations on them. It could calculate the average moisture for each field, find the lowest temperature recorded, or identify any readings that are outside a normal range. This is where the raw numbers turn into useful insights. That, in some respects, is the real magic happening.
Once Glue has finished its calculations, it can then take the summarized information and put it into another location. This might be another S3 bucket, but this time for processed information, or perhaps a database like Amazon Redshift, which is good for analytical queries. The farmer can then access this processed information through a simple dashboard or a report that is generated from the database. This means the farmer gets a clear, easy-to-understand summary of what happened with their fields overnight, without having to look at every single raw sensor reading. It is, you know, a complete cycle from raw data to actionable insights.
Putting Together a Remote IoT Batch Job
So, when you bring all these pieces together, building a remote IoT batch job example in AWS involves a few key steps. First, you need your actual remote IoT devices out there, gathering the information. These devices must be able to send their readings to AWS. This might involve setting up the devices with the right software to connect to AWS IoT Core. This is, you know, the physical layer of the whole system.
Next, you set up AWS IoT Core to receive all that incoming information. You create rules within IoT Core that tell it where to send the data. For a batch job, the typical destination for raw data is Amazon S3. S3 is designed for storing large amounts of data reliably and at a low cost, which is perfect for collecting all those sensor readings over time. It is, for the most part, the central holding area for your information before it gets processed.
Finally, you set up the batch processing part. This usually involves scheduling a job, perhaps using AWS Lambda or a simple cron job that triggers an AWS Batch or AWS Glue process. This job will then read all the accumulated data from S3, perform the necessary calculations or analysis, and then store the processed results in a format that is easy to use, like a summary file in S3 or a table in a database. This entire setup allows for efficient and cost-effective processing of large volumes of remote IoT information, making it very useful for many real-world applications. That, actually, completes the picture of a remote IoT batch job example in AWS.
- Unveiling The Wealth Of A Multitalented Star Harry Connick Jr Net Worth
- Exploring The Magic Of The James Taylor Tour
- Unmasking The Legacy Of Christian Bale As Batman
- Unraveling The Mystery Who Is Kellen Moores Wife
- Exploring The Mystique Of The 20 April Star Sign

Efficient Batch Computing – AWS Batch - AWS
AWS Batch Implementation for Automation and Batch Processing
AWS Batch Implementation for Automation and Batch Processing
